
TL;DR:
- Memory-enabled chatbots retain user preferences and conversation history for personalized interactions.
- Different architectures like vector store and entity memory optimize long-term engagement and data relevance.
- Proper memory management involves balancing recall with privacy, relevance, and intelligent forgetting.
Most people assume chatbots are forgetful by design. They picture a bot that resets after every session, treating each fan like a stranger. But that assumption is outdated. Memory enables persistent context for AI agents, making deeper personalization not just possible but scalable. For content creators and adult site operators, this shift changes everything. A chatbot that remembers a fan’s preferences, past conversations, and personal details doesn’t just respond. It connects. This article breaks down how AI memory works, which architectures matter most, and how you can use these insights to build fan relationships that actually last.
Table of Contents
- What is memory in AI chatbots?
- Core memory architectures: How chatbots remember
- Memory models inspired by human cognition
- Challenges and solutions for maintaining relevant memory
- Expert perspectives: Memory wars and innovation trends
- What most creators miss about chatbot memory
- Elevate fan engagement with advanced chatbot memory
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Memory drives personalization | AI chatbots use memory to transform conversations into engaging, tailored fan experiences. |
| Different architectures matter | Choosing the right memory technology determines how well chatbots recall user preferences and history. |
| Balancing privacy and relevance | Effective chatbot design involves intelligent forgetting and strong privacy safeguards, especially in adult contexts. |
| Innovation is ongoing | Experts are advancing memory systems for smarter, more nuanced fan engagement in chatbots. |
What is memory in AI chatbots?
At its core, most large language models (LLMs) are stateless. That means every conversation starts from zero. No history. No context. No recognition. The model processes your input and generates a response, then forgets the entire exchange the moment it ends. For casual use cases, that’s fine. For fan engagement on platforms like OnlyFans or Fanvue, it’s a serious problem.
Memory-enabled chatbots solve this by storing information between sessions. Memory in AI chatbots enables persistent context across sessions, which means a fan who told your chatbot their favorite content type last Tuesday will still be recognized and catered to next Friday. That’s not a small upgrade. It’s the difference between a generic auto-reply and a genuine conversation.
Here’s what memory-enabled chatbots can store:
- Conversation history: Full or summarized logs of past interactions
- User preferences: Content types, communication style, frequency of contact
- Learned facts: Names, birthdays, relationship milestones fans share voluntarily
- Behavioral patterns: When fans are most active, what triggers engagement or drop-off
For adult content creators, this is especially powerful. Fans who feel remembered are more likely to convert from free DMs to paid subscriptions. They’re also less likely to churn. A bot that greets someone by referencing their last conversation creates a sense of intimacy that generic messaging simply cannot replicate.
“Memory transforms a chatbot from a transactional tool into a relationship-building engine. That’s the real value for creators.”
Pro Tip: Start by identifying the three most important facts you’d want to remember about each fan, such as their content preferences, how long they’ve been following you, and any personal details they’ve shared. Build your memory strategy around those first.
If you’re still figuring out where to start, comparing memory types available on modern platforms can help you choose the right approach for your audience.
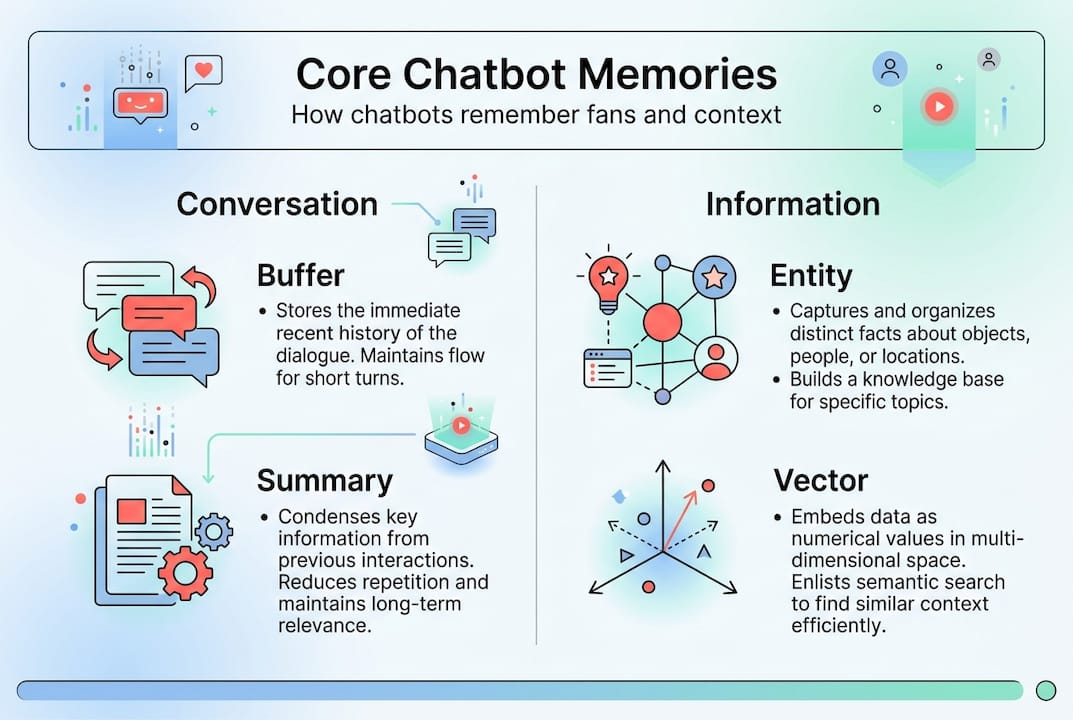
Core memory architectures: How chatbots remember
Not all memory works the same way. Conversation Buffer, Summary Memory, Entity Memory, and Vector Store Memory are core memory architectures that power different kinds of chatbot recall. Each has distinct strengths and trade-offs depending on your use case.
Conversation Buffer stores the entire conversation history in the active context window. It’s thorough but expensive. Long conversations eat up context space fast, which can slow responses or hit token limits.

Summary Memory condenses past exchanges into a shorter digest. Instead of storing every message, it keeps a running summary. This saves space but can lose nuance, especially in emotionally rich fan conversations.
Entity Memory focuses on specific entities, like people, preferences, or topics. It tracks key facts about each user rather than the full conversation. Efficient and targeted.
Vector Store Memory converts past conversations into numerical representations and stores them in a searchable database. Vector store retrieval enables efficient long-term personalization by pulling only the most relevant memories when needed, rather than loading everything at once.
| Memory type | Strength | Limitation | Best for fan engagement |
|---|---|---|---|
| Conversation Buffer | Complete history | High token cost | Short, intense fan sessions |
| Summary Memory | Space-efficient | Loses detail | General fan updates |
| Entity Memory | Precise recall | Limited scope | Tracking fan preferences |
| Vector Store | Scalable, semantic | Setup complexity | Long-term personalization |
For adult site operators managing hundreds or thousands of fans, Vector Store and Entity Memory are the most practical combination. Vector Store gives you semantic search across long histories. Entity Memory keeps the most important facts front and center.
- Use Entity Memory to track fan names, preferences, and key milestones
- Use Vector Store to retrieve relevant past conversations during new interactions
- Combine both to create a layered memory system that feels natural
Pro Tip: Don’t rely on a single memory type. Layering Entity Memory with Vector Store gives your chatbot both precision and depth, which is exactly what fans expect from a personalized experience.
Exploring the chatbot memory features available on purpose-built platforms can save you significant setup time compared to building from scratch.
Memory models inspired by human cognition
With core architectures covered, it’s useful to look at how memory in chatbots draws inspiration from the human mind. AI memory systems mirror human cognition across four key types: short-term, episodic, semantic, and procedural. Understanding these parallels helps you design smarter fan engagement strategies.
Short-term or working memory maps to the chatbot’s active context window. It holds what’s happening right now in the conversation. Limited in size, it’s cleared when the session ends unless deliberately saved.
Episodic memory recalls specific events or interactions. A chatbot with episodic memory might remember that a fan celebrated a birthday last month or mentioned they were going through a tough week. These details make conversations feel warm and human.
Semantic memory stores general facts and preferences. This is where fan profiles live: their content tastes, communication style, and long-term interests.
Procedural memory captures learned workflows. If a fan always prefers voice-note style responses, the chatbot learns that pattern and applies it automatically.
| Human memory type | Chatbot equivalent | Fan engagement example |
|---|---|---|
| Short-term | Context window | Tracking the current conversation topic |
| Episodic | Session logs | Recalling a fan’s last purchase or message |
| Semantic | User profile | Storing content preferences and interests |
| Procedural | Behavioral patterns | Adapting tone based on fan communication style |
“The most effective AI companions don’t just store data. They recall the right memory at the right moment, just like a person who genuinely pays attention.”
For adult content creators, episodic and semantic memory are the most impactful. Episodic memory creates emotional continuity. Semantic memory ensures every interaction feels tailored rather than templated.
Challenges and solutions for maintaining relevant memory
Understanding cognitive parallels is helpful, but memory management comes with real-world challenges that must be handled smartly. The biggest one is context dilution. As conversation histories grow longer, the signal-to-noise ratio drops. Irrelevant old messages crowd out the details that actually matter, reducing the quality of responses.
Intelligent forgetting is needed to prune irrelevant data, since context dilution reduces precision over time. Systems like MaRS (Memory-Augmented Retrieval Systems) use automated pruning to remove stale or low-value memories, keeping the active memory lean and accurate.
Privacy is the other major challenge. Persistent memory risks data exposure, especially in adult content environments where fans share sensitive personal information. A data breach in this context isn’t just a technical problem. It’s a trust catastrophe.
Here’s a numbered action plan for managing memory safely:
- Use namespaces and user IDs to isolate each fan’s data from others
- Set retention limits so old or irrelevant data is automatically purged after a defined period
- Maintain audit trails so you can review what’s stored and delete it on request
- Encrypt stored memory at rest and in transit to minimize exposure risk
- Communicate transparently with fans about what your chatbot remembers and why
Key stat: Platforms that implement structured forgetting policies report significantly fewer data compliance issues compared to those using raw, unmanaged memory storage.
Pro Tip: Treat fan memory data the same way you’d treat financial records. Store only what you need, protect it rigorously, and have a clear deletion process ready before you ever need it.
Expert perspectives: Memory wars and innovation trends
Knowing the challenges, let’s look at what experts and innovators are doing to advance chatbot memory. Expert views contrast graph-based, OS-inspired, and observational memory models, each offering a different philosophy for how AI should remember.
Graph-based memory (used by tools like Mem0 and Zep) maps relationships between entities. Instead of storing isolated facts, it tracks how people, topics, and events connect. For fan engagement, this means your chatbot can understand not just what a fan likes, but how those preferences relate to each other.
OS-inspired memory (pioneered by MemGPT and its successor Letta) treats memory management like an operating system manages RAM. The chatbot actively decides what to keep in fast-access memory and what to archive. This self-managed context allows for much longer, more coherent conversations without hitting token limits.
Observational memory (as seen in Mastra) focuses on compression and efficiency. Rather than storing everything, it observes patterns and distills them into compact, high-value summaries.
Practical implications for fan engagement:
- Graph-based models excel at understanding fan relationship dynamics and content preferences over time
- OS-inspired models are ideal for creators managing deep, ongoing fan relationships that span months or years
- Observational models work well for high-volume operators who need efficiency without sacrificing personalization
“The future of fan engagement isn’t about chatbots that remember more. It’s about chatbots that remember better.”
The debate between these schools isn’t academic. The architecture you choose directly affects how personal, how scalable, and how trustworthy your fan chatbot feels.
What most creators miss about chatbot memory
Here’s the uncomfortable truth: most creators obsess over how much their chatbot can remember, when they should be focused on how well it remembers. Volume of stored data is not the same as quality of personalization. A chatbot holding 10,000 messages of fan history isn’t automatically better than one holding 50 carefully curated facts.
The best fan engagement systems we’ve seen don’t try to remember everything. They prioritize relevance. They know which details actually change how a fan feels during a conversation, and they surface those at exactly the right moment. That’s a design decision, not a technical one.
Many operators also underestimate the value of personalized chatbot engagement built on intelligent forgetting. Letting go of irrelevant data isn’t a failure. It’s a feature. A chatbot that forgets noise and remembers signal will always outperform one drowning in its own history.
Pro Tip: Audit your chatbot’s memory quarterly. Remove anything that no longer reflects the fan’s current preferences or relationship stage. Fresh, relevant memory beats a bloated archive every time.
Elevate fan engagement with advanced chatbot memory
The insights above point to one clear conclusion: memory is the foundation of meaningful fan engagement. Without it, every interaction starts from scratch. With it, your chatbot becomes a relationship tool that grows smarter and more personal over time.
Persona AI for personalized chatbots gives content creators and adult site operators a ready-built platform to deploy memory-rich chatbots across OnlyFans, Fanvue, Instagram, and more. You don’t need to code anything or choose between memory architectures manually. The platform handles persistent memory, fan profiling, and intelligent recall so you can focus on content. Start building a chatbot that actually remembers your fans and watch what happens to your retention and revenue.
Frequently asked questions
How does memory improve AI chatbot personalization?
Memory enables persistent context for deeper personalization by letting chatbots recall user history, preferences, and shared facts across sessions. This makes every conversation feel tailored rather than generic.
What are the main risks of using memory in chatbots for adult content?
Persistent memory risks data exposure, making strong data management, encryption, and clear forgetting policies essential for adult content operators. Fan trust depends on how responsibly you handle their information.
How do chatbots decide what to remember and what to forget?
Modern systems use intelligent forgetting to prune irrelevant or stale data automatically, which improves both response precision and compliance with data regulations.
What memory architecture is best for fan engagement?
Vector store memory enables efficient long-term personalization, and when combined with entity memory, it gives fan chatbots both scalable recall and precise, preference-based responses.